
Resumen
- Existen varios problemas que se pueden resover con algoritmos de aprendizaje computacional: Regresión, clasificación, y segmentación / localización de objetos.
- Independientemente del problema, los algoritmos de aprendizaje computacional supervisado requieren de los siguientes elementos: Datos históricos y sus etiquetas, una función de costo, la definición de un modelo predictivo, y un algoritmo de optimización.
Aprendizaje computacional
El objetivo del aprendizaje computacional supervisado (supervised machine learning) es hacer predicciones acertadas. Por ejemplo, identificar en una imagen de resonancia magnética si hay un tumor presente, o bien, estimar el precio de compra de una casa dadas una serie de características tales como el número de habitaciones, tamaño del terreno, etc.
Para hacer estas predicciones, los algoritmos de aprendizaje computacional necesitan analizar una serie de datos históricos. Posteriormente, buscan patrones en dichos datos, y finalmente usan esos patrones para hacer predicciones. La siguiente figura ilustra este proceso.

Tipos de predicciones
De manera general, existen tres tipos de predicciones que podemos hacer por medio del aprendizaje computacional supervisado:
- Regresión: Cuando la predicción es una cantidad (número real). Este es el caso de nuestro ejemplo de predicción de precio de venta de la casa.
- Clasificación: Cuando la predicción consiste en clasificar los elementos en una de C posibles categorías. En el caso de una imagen médica dichas categorías pudieran ser: (A) No hay tumores, (B) Tumor maligno, (C) Tumor beningno.
- Segmentación o detección de objetos: Consiste en identificar en una imagen, video, audio o señal la localización de un objeto de interés. Por ejemplo, la segmentación de tumores en una imágen cerebral.
Independientemente del tipo de predicción, existen una serie de elementos comunes en todas las tareas de aprendizaje computacional. Todas estas tareas tienen el formato: $$y = f(x)$$, donde 

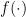
El problema principal es que no conocemos cuál es la función 

Modelos paramétricos
La forma más común de encontrar dicha aproximación es el uso de modelos paramétricos. Dichos modelos pueden ser tan sencillos como un modelo de regresión lineal, o tan complejos como una red neuronal. Volviendo al ejemplo de predecir el valor de una casa, podemos usar el siguiente modelo:
$$\hat{y} = \hat{f}(x) = \alpha_0 + \alpha_1 x_1 + \dots \alpha_n x_n \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1)$$
donde 




La ecuación (1) representa a una familia de ecuaciones lineales. Existen un número infinito de miembros en dicha familia, por ejemplo, uno de los miembros es cuando todos los coeficientes 



Optimización y función de costo
Para poder determinar qué coeficientes son los mejores, necesitamos definir el concepto de “mejor”. Este es el propósito de la función de costo, 
$$\mathcal{L}(y, \hat{y}) = (y \ \ -\ \ \hat{y})^2$$
Los “mejores” coeficientes
Elementos del aprendizaje computacional
En conclusión para resolver un problema de predicción por medio del uso de algoritmos de aprendizaje computacional, necesitamos los siguientes elementos:
- Datos históricos: Es el conjunto de datos que serán usados por el algoritmo de aprendizaje computacional para determinar los mejores parámetros del modelo de predicción. Cada elemento de estos datos históricos está definido por una serie de atributos.
- Etiquetas: Son los valores a predecir,
- Función de costo: Es una ecuación que mide la diferencia entre el valor estimado por nuestro modelo, y el valor real de cada uno de los elementos del set de datos históricos.
- Modelo predictivo: También llamado set de hipótesis, es el modelo matemático que usamos para hacer las predicciones. Ejemplos de este tipo de modelos son regresión lineal, regresión logística, redes neuronales, etc.
- Algoritmo de optimización: Es el algoritmo que usamos para encontrar los parámetros de nuestro model predictivo que optimizan la función de costo.
Un comentario en “Entendiendo los elementos básicos de machine learning”
Comentarios cerrados.